一、简述
1. 传统式WAF的困扰
传统式的WAF,依赖标准和黑与白名册的方法来开展Web攻击检验。该方法太过依赖安全性工作人员的基础知识深度广度,对于不明攻击种类万般无奈;另一方面即使是给定的攻击种类,因为正则关系式与生俱来的局限,及其shell、php等语言表达极为灵便的英语的语法,理论上便是可以绕开,因而误拦和漏拦是与生俱来存有的;而提升正则精确性的结果便是加上大量精细化管理正则,从而深陷一个永无止尽修复漏洞的涡旋,连累了总体特性。
对于以上问题,现阶段流行安全性生产商的研究内容大致分成2个势力:语义解析和AI鉴别。

2. 语义解析
从http负载中提炼的疑是可实行字符串常量,用沙盒去解析下看是不是可以实行。
针对常用的shell命令cat而言,假如用shell的英语的语法去了解,cat c’a't c”’a”’t ””c’a’t””全是一回事儿。语义了解理论上可以彻底解决一部分正则少报乱报问题,但是也具有一些难题。例如http协议中哪一部分是疑是可实行的字符串常量,http协议中怎样断开和拼凑才可以确保一切正常解析,这种是非常繁琐的;此外sql语法、sehll英语的语法、js语法还必须各自完成。
就Libinjection语义解析库的看来,就会有许多状况的绕开和漏拦,而且它自身也应用到了标准,在传统式WAF标准的基本上干了一层抽象化,换了一种标准的辨别方法。实际上目前市面上早已发生了一些根据语义的WAF宣传口号也很洪亮,到底市场前景怎样现在还没有很明亮。
3. AI鉴别
有一些AI的拥趸者,开朗地觉得人工神经网络、深度神经网络是化解传统式WAF困扰的最终解决方法,额…也许吧,或许仅仅如今还没创造发明出一个非常极致的AI解决方法。即使如此,纯粹就人工神经网络为WAF颠覆式创新层面看来,或是有一片广阔天地。
在安全性鉴别行业,人们运用AI技术性,以统计数据为媒体,将结构出的具备区别工作能力的特点开展数学课表述,随后根据练习实体模型的形式使之具有区别优劣的工作能力。
因而,实体模型的优劣最后在于数据信息的品质和特点的优劣,他们决策了实体模型所能实现的上界,而优化算法则是因为让实体模型去试着持续碰触这一上界。
svm算法便是一个“发掘自然界幸福规律性的全过程”,某一类特点可以区别相对性应具有此类特点的攻击种类,关键是这一类特点怎样选择既能让实体模型有不错的分辨工作能力,与此同时又具有较好的广泛能里和实用性,乃至是对不明攻击种类的分辨工作能力。
相对性于图像识别技术、语音识别技术等行业,AI在Web安全方面的运用发展略晚,运用也不足深彻。归根结底,人工神经网络对Web安全的鉴别精确度和可扩展性尚不可以极致取代传统式的WAF标准;根据正则配对的安全防护,眼见为实,维护保养即起效。因而,运用AI开展Web攻击鉴别若要增强其适用范围需从下列这几个大方向下手:
- 提升精确度
- 提升逻辑性,提升特性
- 实体模型的高效率自身更新迭代
- 对不明攻击种类的鉴别
二、Web攻击现状分析
先来说下攻击样例:
XSS跨站脚本制作:
SQl引入:
指令实行:
可以看得出Web攻击要求的特点大致分成2个方位:
- 危害关键词特点:如
- select,script,etc/passwd
- 不标准结构类型:如
- ${@print(eval($_post[c]))}
1. 根据情况变换的构造svm算法
大家大多数的作法是将具备类似特性的标识符广泛为一个情况,用一个固定不动的标识符来替代。如:英文字母广泛为’N’、中文字符泛化为’Z’、数据广泛为’0’、分隔符泛化为’F’等。其核心内容是,用不一样的模式去表述不一样的标识符特性,尽量让在Web攻击中具备含意的字段与别的标识符区别起来,随后将一个payload转化成一连串的情况链去练习出一个几率变换引流矩阵。
常见的建模是隐马尔可夫链实体模型。假如用黑样版练习HHM实体模型,可以完成以黑找黑的目地,那样的益处是错判较低;用白样版练习HHM实体模型,则能发觉不明的攻击种类,但与此同时会出现较高的错判。在运用搜集好的训练样本检测的过程中发觉,对于一部分XSS攻击、插入分隔符的攻击变异这种在要求主要参数构造上具有显著特点的Web攻击主要参数,该方法具有较好的分辨工作能力;而对无结构类型的SQL引入或是比较敏感文件目录实行无法识别,这也符合实际预估。
殊不知,该方法存有一个著名的缺点:从要求主要参数构造非常的视角去观查,结构体出现异常不一定全是Web攻击;结构体一切正常不确保并不是Web攻击。
(1)构造出现异常xss攻击 ——> 鉴别
(2)构造出现异常形变xss攻击 ——> 鉴别
(3)构造出现异常sql注入 ——> 鉴别
(4)构造一切正常sql注入 ——> 无法识别
(5)构造出现异常一切正常要求 ——> 错判
(6)构造出现异常一切正常要求 ——> 错判
(7)构造出现异常一切正常要求 ——> 错判
2. 根据统计量的结构类型
对URL要求获取特点,如URL长短、途径长短、主要参数一部分长短、主要参数名长短、变量值长短、主要参数数量,主要参数长短占有率、特殊符号数量、风险特殊符号组成数量、高风险特殊符号组成数量、途径深层、分隔符数量这些这种数量指标做为特点,实体模型可以挑选逻辑回归、SVM、结合数优化算法、MLP或是无监督学习实体模型。
若只拿单独网站域名的url要求做认证该实体模型有还行的主要表现;殊不知大家应对的是企业集团不计其数的系统软件网站域名,不一样的网站域名主要表现出不一样的URL文件目录等级、不一样的取名习惯性、不一样的要求主要参数…对于那样极为繁杂的业务场景,在以上特点行业,数据信息自身便会出现很多的模棱两可。那样,对于全栈的url要求实体模型区别实际效果较弱,准确度也太低。即时上,即使有较优良的兼容自然环境,相对性纯粹的情景,实体模型准确度也难以提高到97%以上。
3. 根据中文分词的源代码精彩片段特点
依据指定的中文分词标准,将url要求切成片,运用TF-IDF开展svm算法,并保存具备区别工作能力的关键词组成特点,与此同时融合在网上开源系统进攻样版尽量健全特点。在这儿怎样“高质量”中文分词和特点关键词组成的构造密切相关,是逻辑回归模型的关键,必须融合中后期实体模型主要表现結果不断地调节健全(下面关键叙述)。
事实上,保存的特性全是些Web进攻之中常用的风险关键词及其标识符组成,而这种关键词及标识符组成是有局限的。理论上,融合现阶段所具有的大量浏览总流量和WAF充足的Web进攻样版,几乎能所有遮盖的这种关键词及标识符组成。
三、根据中文分词的svm算法和MLP实体模型
依据全能类似定律Universal approximation theorem(Hornik et al., 1989;Cybenko, 1989)叙述,神经元网络理论上能以随意精密度你跟随意复杂性的函数公式。
1. 逻辑回归模型
- 编解码:递归法URL编解码、Base64解码、十进制十六进制编解码;
- 标识符广泛:例如将数据信息统一广泛为“0”,英文大写字母转小写字母等实际操作;
- 事情配对:XSS进攻的payload包括标识和事件,这儿把同一种类的事情或是标识搜集起來,根据正则表达式开展配对,并将它换成一个自定标识符组成放进词袋模型;
- 关键词配对:相近上边事情配对的基本原理,将同一类具有同样特性的关键词广泛成一个字符组成,并资金投入词袋模型,那样做的益处是可以降低特点层面;
- 变换矩阵的特征值:将一个样版根据编解码、中文分词、配对转化成由“0”和“1”构成的固定不动尺寸的矩阵的特征值。
2. 实体模型实际效果
为了更好地降低篇数,这儿只给予svm算法的基本思路和实体模型的评估結果。
随机森林:
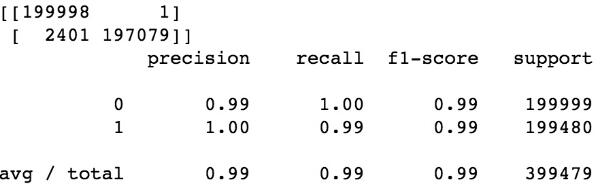
逻辑回归:
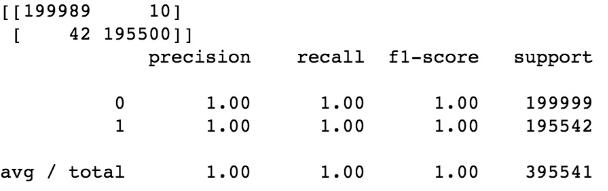
MLP实体模型:
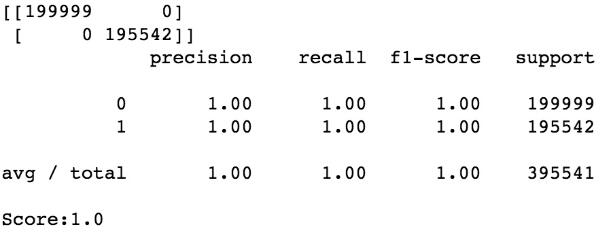
3. 总结
缺陷:
- 必须模型拟合不断校检,提升获取特点转换方法;
- 对不明进攻种类鉴别实际效果差;
- 对形变进攻鉴别失效;
- 沒有了解到关键词的时钟频率信息内容。
针对常用的shell了指令cat而言,假如用shell的英语的语法去了解,cat c’a't c”’a”’t ””c’a’t””全是一回事儿。这儿中文分词的MLP实体模型能了解cat,但对形变的c’a't这种没法了解(中文分词毁坏信息内容)。
优势:
- 相对性深度神经网络而言具备更高效率的预测分析高效率;
- 相对性深度神经网络实体模型,分布式部署更为方便快捷,扩展性强,能融入大量的浏览总流量;
- 准确度高,保证对已经知道种类的彻底鉴别;
- 可扩展性强,只需把漏拦和误拦的要求种类激光打标后再次资金投入练习就可以。
对于上边的根据关键词特点的MLP实体模型,很有可能有些人会发生疑惑,为何能获得类似100%的准确度?这也是不断调节的結果。小编在做矩阵的特征值变换以前对url要求干了很多广泛和清理的工作中,也使用了正则表达式。早期对于鉴别错判的要求,会根据调节词袋空间向量层面和url清理方法,充足发掘出正负极样版的差别特点,以后再开展空间向量变换,进而尽可能确保键入给实体模型的训练样本是沒有模棱两可的。在实体模型发布期内,对于每日造成的错判种类,会在调节svm算法后,做为正样版再次资金投入训练集并升级实体模型。根据一点一滴的累积,让实体模型愈来愈健全。
四、鉴别形变和不明进攻的LSTM实体模型
根据以上三种svm算法构思,挑选实际效果最好的中文分词方法练习MLP实体模型,可以练习获得一个函数公式和主要参数组成,能达到对已经知道进攻种类的彻底鉴别。但鉴于该MLP实体模型的svm算法发哪个是,一部分依靠标准,导致理论上始终存有漏拦和错判。由于对鉴别总体目标而言样版始终不是全面的,必须人力持续的Review,发觉新的拒绝服务攻击,调节svm算法方法,调节主要参数,重练习…这条道路好像始终沒有终点。
1. 为何挑选LSTM
回望下以上的Web进攻要求,安全性权威专家一眼便能鉴别进攻,而设备学习模型必须大家人力来告知它一系列有区分度的特点,并应用样版数据信息融合特点,让ML模型模拟出一个函数公式获得一个是与非的輸出。
安全性权威专家见到一个url要求,会按照本身脑子里的“工作经验记忆力”来对url要求开展了解,url要求构造是不是一切正常,是不是包括Web进攻关键词,每一个精彩片段有什么含义…这种都根据对url要求每一个标识符前后文的了解。传统式的神经元网络做不到这一点,殊不知循环系统神经元网络可以实现这一点,它容许信息内容不断存有。
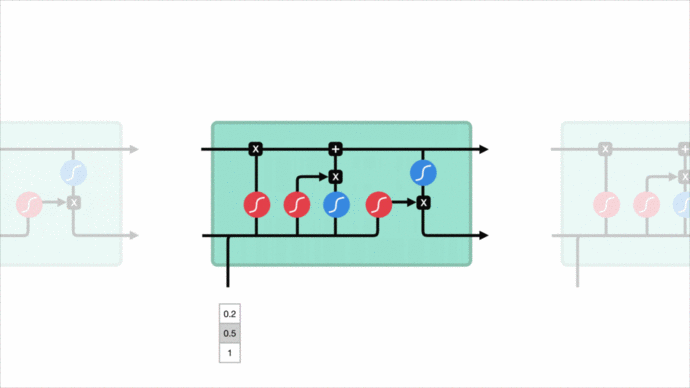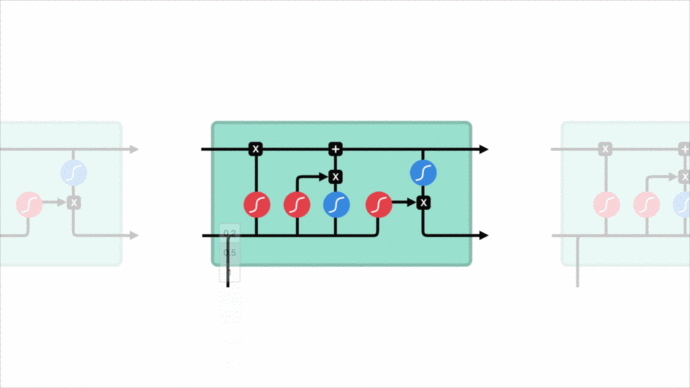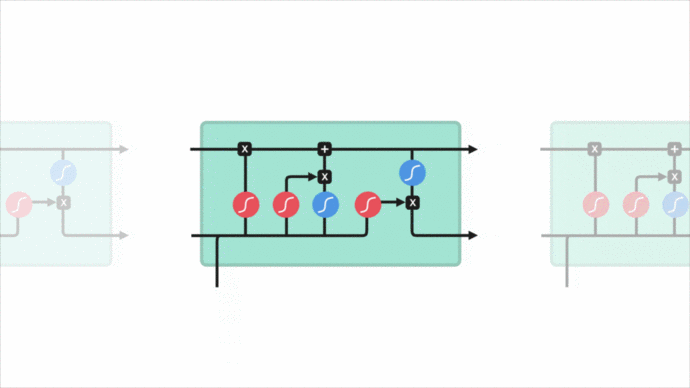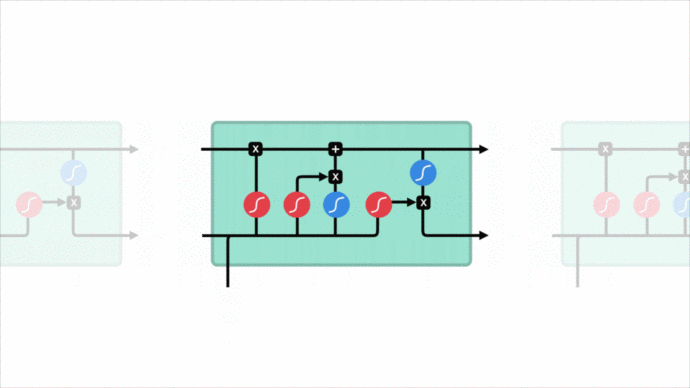
恰好运用LSTM对前后文了解优点,运用url要求的前后左右标识符分辨是不是为Web进攻。这一益处是可以省掉逻辑回归模型这一复杂的全过程。
恰好是这类对url要求特点的了解方法,让它具有了一定对不明进攻的分辨工作能力。对于不明进攻形变而言,中文分词的MLP实体模型能了解cat,但对形变的 c’a’t则没法了解,由于中文分词会把它切分起来。而LSTM实体模型把每一个标识符作为一个特点,且标识符间有前后文联络,无论cat 、c’a't 或 c”’a”’t 、””c’a’t””,在通过置入层的变换后,有着类似的矩阵的特征值表述,模型拟合而言全是类似一回事儿。
2. 矩阵的特征值化和实体模型练习
这儿仅对变量值要求的变量值开展练习。
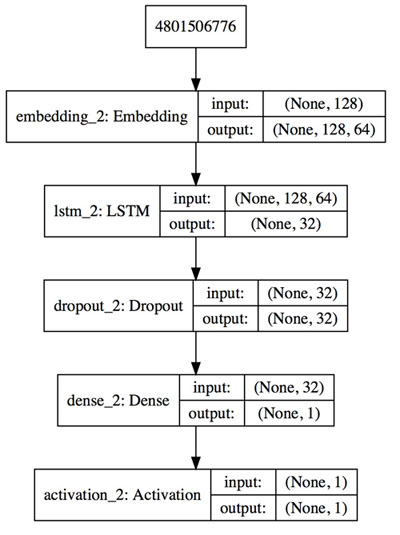
3. 实体模型评定
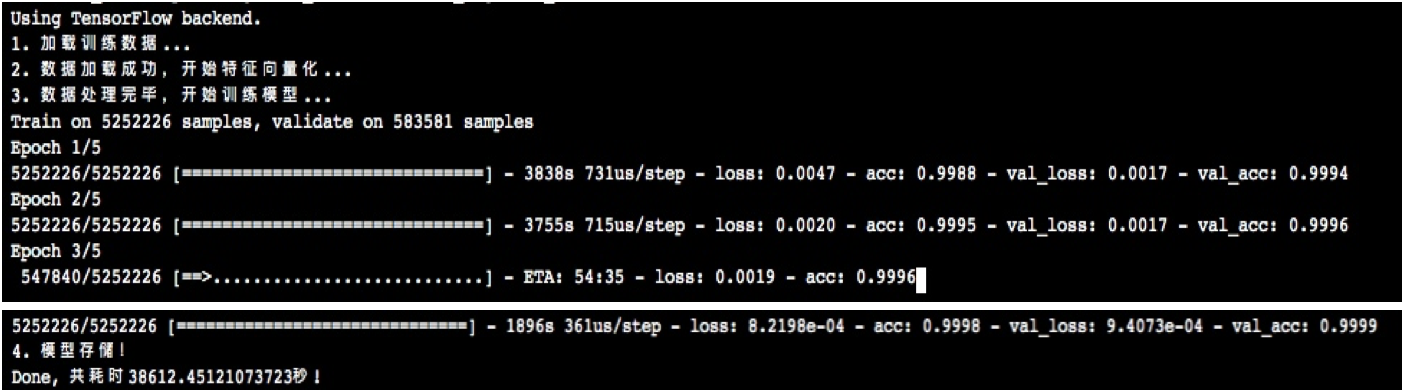
检测时样本数为10000时,精确度为99.4%;
检测时样本数584万时,通过GPU练习精确度做到99.99%;
经观查鉴别不正确样版,大多数因长短激光切割的因素导致url精彩片段是不是具备进攻用意不太好定义。
4. 总结
缺陷:
- 資源花销大,预测分析高效率低;
- 实体模型必须同样规格的键入;前文对超过128byte的url要求开展激光切割,对低于128byte的开展补0,这类呆板的分割方法有可能毁坏url初始信息内容。
优势:
- 不用繁杂的逻辑回归模型;
- 具有对不明进攻的分辨工作能力;
- 泛化能力强。
五、一点思索
小编由于作业的必须,试着了很多种多样检验Web进攻的方位及特点的获取方法,可是也没有获得能令我十分令人满意的实际效果,乃至有时也会对某一方位它自身具有的缺点难以忍受。传统式人工神经网络方式去做Web进攻鉴别,十分依靠逻辑回归模型,这耗费了我大部分時间并且还要不断着。
现阶段除开LSTM实体模型之外,苏宁易购的工作环境中表現最好是的是MLP实体模型,但它自身也普遍存在着明显的缺点:由于这一实体模型的svm算法是根据Web进攻关键词的,在做svm算法的情况下,为了确保鉴别的精确度迫不得已应用很多正则表达式来开展中文分词、开展url广泛清理,可是这类方式实质上跟根据标准的WAF沒有很大差别。唯一的益处是多带来了一种不完全一致的检测方式进而鉴别出去一些WAF标准漏拦或是误拦的种类,进而对标准库完成更新维护保养。
长久看来我觉得前文的LSTM检验方位是最有前景的;这儿把每一个标识符作为一个矩阵的特征值,理论上只需给它饲养的样版充足充分,它会自身了解到一个字段名组成,发生在url的什么位置处所代表的含意,想真真正正的安全性权威专家一样保证一眼就能鉴别出攻击,不论是哪些变种的攻击。